Rather than spending the time drawing ugly stick men so to speak (I can't draw very well) I'm going to refer to the Common Application Architecture shown in Chapter 3: Architecture Design Guidelines of Microsoft's patterns & practices Application Architecture Guide 2.0 (The Book):
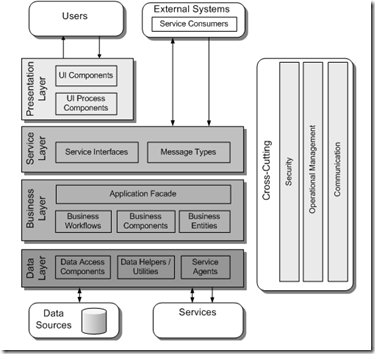
I plan on working my way from the bottom up. It's possible to take a different approach - a BDUF will allow multiple teams to work in parallel assuming the contracts between the layers are well-defined. For a data source I'll be using the Adventure Works LT sample database because it's a simple design and comes both pre-built and pre-populated. You can find documentation, the downloadable installers and a schema diagram for the database here on CodePlex.
Originally I installed AWLT on my local SQL 2008 Express instance however I kept getting "Must declare scalar variable..." errors using the technique I'm about to discuss. Since I have a full SQL 2005 Standard Edition instance running on another machine, I simply loaded the appropriate AWLT 2005 version onto it then changed the connection string and I was cooking. I didn't change anything in my code so one has to wonder if the two versions of the database are different or if the database servers behave differently. Having wasted over an hour chasing around trying to fix the error, I decided to pass for now and use the SQL 2005 instance. The goal isn't to become a SQL DBA here or study/debug the nuances of SQL 2008 Express but rather to explore the various layers of a complex .NET application in a pragmatic, approachable way.
I'm going to use the Active Record pattern because it allows flexibility that will be explored later on. An alternate and well-known approach is to generate strongly-typed DataSets using the tools in Visual Studio instead. You'll find information here and here as well as plenty more examples of that approach simply by searching. With the Active Record pattern used here, a data access class is built that models in code a single table. Essentially the class contains public properties corresponding to the columns in a table and methods for CRUD behavior of that data.
Creating an instance of an Active Record class means it will have one of two states: either with existing data loaded from storage or a new instance with default values (data does not exist in storage). Therefore, the constructors for the class are pretty straightforward:
public Customer()
{
InitializeData();
}
public Customer(int customerId) : this()
{
Load(customerId);
}
As you can see the default constructor creates an empty instance by calling InitializeData() while passing an identifier, customerId in this case, to the constructor causes the class to Load() the instance data from storage.
As mentioned, this class needs properties that correspond to the columns in its underlying table. A few properties are shown here:
private System.Int32? _customerId;
public System.Int32? CustomerId
{
get { return _customerId; }
set { _customerId = value; }
}
private NameStyleValue _nameStyle;
public NameStyleValue NameStyle
{
get { return _nameStyle; }
set { _nameStyle = value; }
}
private System.String _title;
public System.String Title
{
get { return _title; }
set { _title = value; }
}
For the purposes of this tutorial the properties are simple values that hold data. Of course, business requirements and local development standards may dictate that validation be included as well as other nifty things. Note that the first property shown, CustomerId, is nullable. This is a simple technique to indicate whether or not the instance contains new data that has never been written to the database (null value) or previously stored data that has been retrieved (not null). Remember, primary keys should not be nullable so this approach is sufficient. If you prefer to use GUIDs then simply make the data type System.Guid? instead.
The Load() method is called by one of the constructors to retrieve the instance data from underlying storage and populate the properties as shown here:
public void Load(int customerId)
{
string sqlCommand = "SELECT " + _columnNames + " FROM Customer WHERE CustomerId=@CustomerId";
Database db = DatabaseFactory.CreateDatabase(Settings.Default.DatabaseName);
DbCommand dbCommand = db.GetSqlStringCommand(sqlCommand);
db.AddInParameter(dbCommand, "CustomerId", DbType.Int32, customerId);
using (IDataReader dataReader = db.ExecuteReader(dbCommand))
{
if (dataReader != null && dataReader.Read())
{
PopulateData(dataReader);
}
}
}
At this point, I must take a detour from the code at hand to discuss the underlying data access logic. You can embed ADO.NET code directly in your data layer classes, or better yet put that logic into either a utility/helper class or a base class that all the data layer classes inherit from. You'll note that the p&p's architecture diagram shows these as additional "Data Helpers / Utilities". An alternative to writing all that low level plumbing is to use code that is already written, well tested, and vetted by hundreds of other developers which is what I've done. I'm using the pattern & practice group's Enterprise Library to provide the plumbing. Before you groan because of past experiences or snide comments you've heard from others I suggest you take another look at "EntLib". I've watched it "grow up" from the application block days of early .NET and it's become a mature, well-rounded, adult member of our little society. A lot of the dependencies that plagued earlier versions and forced an all-or-nothing approach have been removed. In fact, for this version of our .NET Adventure I'm only using the Data Access Application Block and nothing else. In future posts, I intend to swap out EntLib for other approaches to illustrate that it can be done and that the design techniques I've shown here make it feasible to do so.
Looking back at the code, notice that I'm using embedded SQL statements. I don't wish to engage in the well-worn debate of dynamic SQL vs. store procedures so please let's agree to get along - if I lose a few readers at this point, so be it. One of the reasons I used embedded SQL is because of SQL Compact Edition (SQLCE). As a light-weight, embedded database it has some compelling features but the tiny size comes with a price - it does not support stored procedures. Had I used stored procedures, I would have closed that door never to be opened again without a lot of effort. Not to mention that the various dialects of database code means that stored procedures are difficult to translate - I'm speaking from experience having written many procedures for SQL Server, Oracle, and DB2 which are conceptually similar but strikingly different in syntax and implementation. The dynamic SQL code shown above should support embedded databases as well as others vendors with little or no changes.
I won't go into the basics of the Enterprise Library classes - you can find plenty of examples online. The essence of the Load() method is that it takes a customer Id as a parameter, constructs an SQL SELECT statement filtered with a WHERE clause specifying the customer Id passed and uses a data reader to retrieve the row. If the row was retrieved (e.g. the customer exists) then the PopulateData() private method is called. You may wish to do something different such as throwing an exception or coding the method with a return value used to indicate success or failure. Also note that "_columnNames" used in building the SELECT clause is a string constant containing a comma-separated list of the column names.
PopulateData() simply copies the values returned in the DataRecord into the class instance properties:
private void PopulateData(IDataRecord dataRecord)
{
_customerId = (int)dataRecord["CustomerId"];
_nameStyle = (dataRecord.GetBoolean(1)) ? NameStyleValue.Eastern : NameStyleValue.Western;
_title = (dataRecord["Title"] == DBNull.Value) ? null : (string)dataRecord["Title"];
_firstName = (dataRecord["FirstName"] == DBNull.Value) ? null : (string)dataRecord["FirstName"];
_middleName = (dataRecord["MiddleName"] == DBNull.Value) ? null : (string)dataRecord["MiddleName"];
_lastName = (dataRecord["LastName"] == DBNull.Value) ? null : (string)dataRecord["LastName"];
_suffix = (dataRecord["Suffix"] == DBNull.Value) ? null : (string)dataRecord["Suffix"];
_companyName = (dataRecord["CompanyName"] == DBNull.Value) ? null : (string)dataRecord["CompanyName"];
_salesperson = (dataRecord["SalesPerson"] == DBNull.Value) ? null : (string)dataRecord["SalesPerson"];
_emailAddress = (dataRecord["EmailAddress"] == DBNull.Value) ? null : (string)dataRecord["EmailAddress"];
_phone = (dataRecord["Phone"] == DBNull.Value) ? null : (string)dataRecord["Phone"];
_passwordHash = (dataRecord["PasswordHash"] == DBNull.Value) ? null : (string)dataRecord["PasswordHash"];
_passwordSalt = (dataRecord["PasswordSalt"] == DBNull.Value) ? null : (string)dataRecord["PasswordSalt"];
}
One thing to note is that the _nameStyle property is using an enumeration called NameStyleValue which is included in the class and shown here:
public enum NameStyleValue
{
Western,
Eastern
}
The AdventureWorks database uses a bit column to store the style of the name - Western (First Last) or Eastern (Last, First) so this enumeration is a convenience to make the property easier to work with in code.
To store the instance data into the backing storage system we expose a simple method called Store() shown here:
public int Store()
{
if (_customerId == null)
return StoreNew();
else
return UpdateExisting();
}
Notice the test of the _customerId property to see if it's null - if so, we store a new instance and if not we update an existing instance. Both StoreNew() and UpdateExisting() are internal (private) methods which callers cannot access. Not only does this make the external, public interface to the Active Record class simple but it hides the internal details of what determines "newness" and the different ways the class needs to handle this. Conversely, exposing StoreNew() and UpdateExisting() means the burden is on the calling code to understand the nuances and invoke the proper method which makes the coupling between the data layer and above more brittle.
Let's take a look at the StoreNew() method shown here:
private int StoreNew()
{
// construct insert statement
StringBuilder sb = new StringBuilder();
sb.Append("INSERT Customer (NameStyle,Title,FirstName,");
sb.Append("MiddleName,LastName,Suffix,CompanyName,SalesPerson,");
sb.Append("EmailAddress,Phone,PasswordHash,PasswordSalt) VALUES (");
sb.Append("@NameStyle,@Title,@FirstName,@MiddleName,@LastName,");
sb.Append("@Suffix,@CompanyName,@SalesPerson,@EmailAddress,");
sb.Append("@Phone,@PasswordHash,@PasswordSalt");
sb.Append(")");
// execute insert
Database db = DatabaseFactory.CreateDatabase(Settings.Default.DatabaseName);
DbCommand dbCommand = db.GetSqlStringCommand(sb.ToString());
db.AddInParameter(dbCommand, "NameStyle", DbType.Boolean, _nameStyle);
db.AddInParameter(dbCommand, "Title", DbType.String, _title);
db.AddInParameter(dbCommand, "FirstName", DbType.String, _firstName);
db.AddInParameter(dbCommand, "MiddleName", DbType.String, _middleName);
db.AddInParameter(dbCommand, "LastName", DbType.String, _lastName);
db.AddInParameter(dbCommand, "Suffix", DbType.String, _suffix);
db.AddInParameter(dbCommand, "CompanyName", DbType.String, _companyName);
db.AddInParameter(dbCommand, "SalesPerson", DbType.String, _salesperson);
db.AddInParameter(dbCommand, "EmailAddress", DbType.String, _emailAddress);
db.AddInParameter(dbCommand, "Phone", DbType.String, _phone);
db.AddInParameter(dbCommand, "PasswordHash", DbType.String, _passwordHash);
db.AddInParameter(dbCommand, "PasswordSalt", DbType.String, _passwordSalt);
int rowsAffected = db.ExecuteNonQuery(dbCommand);
if (rowsAffected != 1)
{
throw new DataException("Failed to INSERT new Customer.");
}
// return customer id (more efficient to use sproc with SCOPE_IDENTITY() and out param)
string sqlCommand = "SELECT CustomerId FROM Customer WHERE FirstName=@FirstName "
+ "AND MiddleName=@MiddleName AND LastName=@LastName "
+ "AND CompanyName=@CompanyName "
+ "AND EmailAddress=@EmailAddress";
dbCommand = db.GetSqlStringCommand(sqlCommand);
db.AddInParameter(dbCommand, "FirstName", DbType.String, _firstName);
db.AddInParameter(dbCommand, "MiddleName", DbType.String, _middleName);
db.AddInParameter(dbCommand, "LastName", DbType.String, _lastName);
db.AddInParameter(dbCommand, "CompanyName", DbType.String, _companyName);
db.AddInParameter(dbCommand, "EmailAddress", DbType.String, _emailAddress);
IDataReader dbReader = db.ExecuteReader(dbCommand);
if (dbReader != null && dbReader.Read())
{
_customerId = (int)dbReader["CustomerId"];
}
return _customerId.Value;
}
In summary, this code constructs an SQL INSERT statement using the property values to pass as parameters, executes the statement and then immediately retrieves the row just inserted. This flies in the face of the earlier discussion regarding dynamic SQL vs. stored procedures and may be a compelling reason for you to go the stored procedure route. As soon as the INSERT statement executes there is a mismatch between the row stored in the database and the class instance in memory, specifically the customer id value. The AdventureWorks database uses a default constraint of NEWID() to generate the primary key value which we don't have visibility over. We cannot leave things this way - otherwise we'd have an instance in memory with no primary key while the row in the database has one. As we showed earlier, the primary key is used to determine "newness" - null means it's a new instance and at this moment it is still null. There are a couple of ways to solve this problem. One way is, of course, to switch from using dynamic SQL to using a stored procedure so that the logic inside the procedure can issue a SCOPE_IDENTITY() function call to retrieve the newly generated primary key and return it to the caller (our code here) as an out parameter. Another approach would be to define the primary keys as GUIDs which we could generate in our C# code within the StoreNew() method thus the instance data in memory and the row in the database would have the same value and be identical. Finally, it's worth noting that we could stick with dynamic SQL and wrap the two database calls inside a transaction so that other processes wouldn't "see" the newly inserted row until we read it back to retrieve the customer id. Once that was done we could commit the transaction and both the in-memory and in-storage versions would be the same.
UpdateExisting isn't worth showing here so I'll just describe it briefly. Rather than constructing an INSERT statement it constructs an UPDATE statement with a bunch of SETs for each column.
To recap, I've shown an implementation of the Active Record pattern that supports the following:
- Exposes properties corresponding to the columns in the underlying database table that callers can manipulate.
- Created two constructors - an empty (default) constructor that initializes a new instance and a second one that takes a primary key identifier and uses it to retrieve the instance values from a row in the underlying database table.
- Created Delete (not shown), Load, and Store methods to enable CRUD behavior.
The next installment will be a bit shorter - I'll cover writing unit tests for this data layer class so we can quickly flush out any problems. In addition, I'll briefly mention FxCop and what it can do for us. In the future we will revise this Active Record class as the needs of the other layers drive us to do more.
The code for the project can be downloaded from here.













